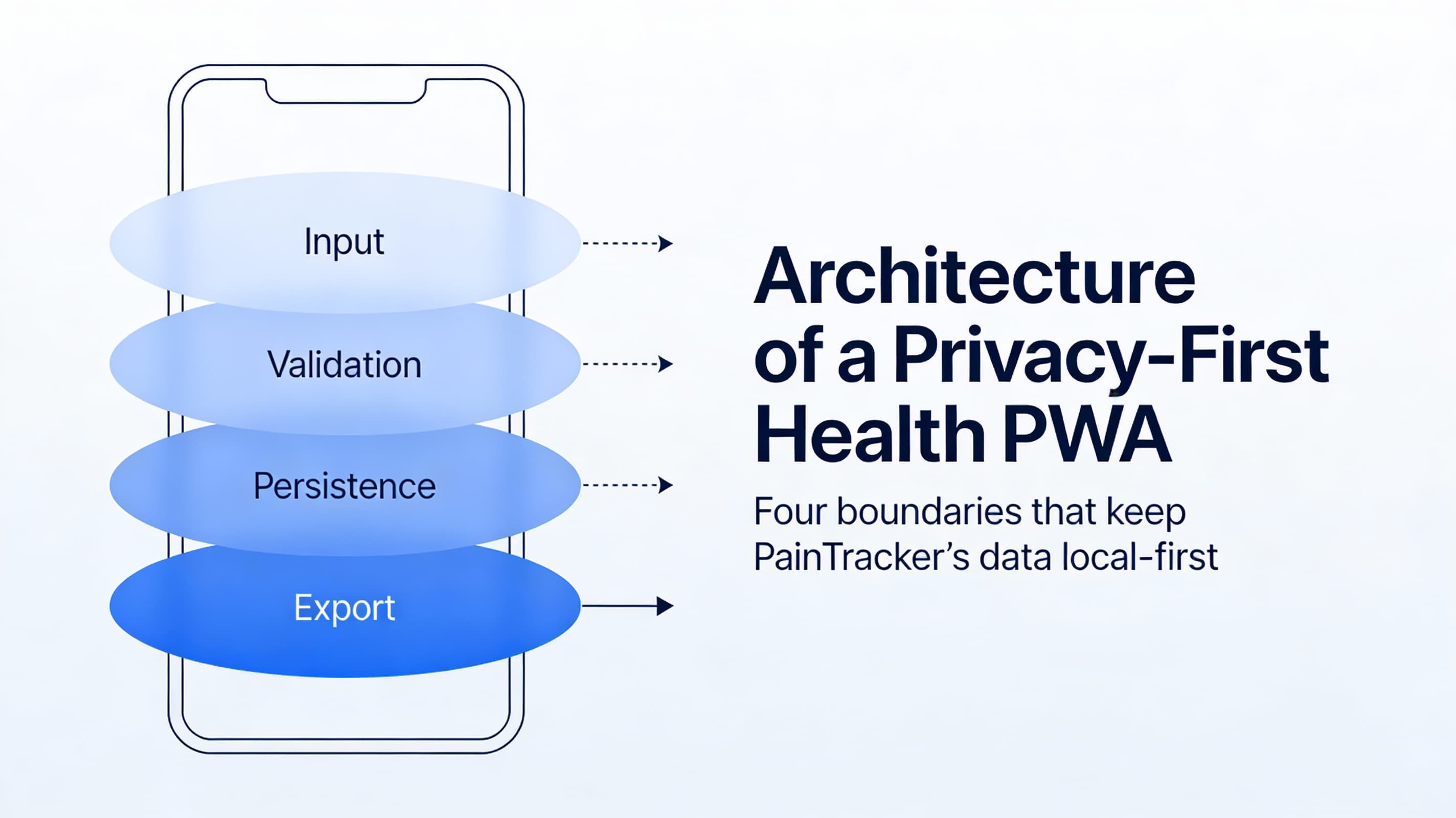
Architecture of a Privacy-First Health PWA

If someone searches for privacy-first health app architecture, the first answer they need is simple: where the data lives, when it moves, and what leaves the device.
PainTracker’s architecture is built around that answer. Health data stays local-first by default, input and validation boundaries are explicit, persistence is predictable, and exports happen only when the user chooses.
At some point, a user will wonder: “Where does this data live?” A privacy-first architecture is how you answer that question clearly—without hand-waving.
When you build a health app, you’re not just choosing a stack.
You’re deciding where someone’s sensitive data lives, how long it stays there, who can get to it, and what kinds of failures you’re willing to tolerate.
A privacy-first architecture is less about “having encryption” and more about having clear boundaries: where data is created, where it is persisted, when it moves, and how you prove (to yourself and to users) that it doesn’t leak.
Here’s a high-level architecture that matches PainTracker’s constraints:
- offline-first as a reliability guarantee
- local-first as a privacy default
- accessibility as a product requirement, not a QA step
The simplest mental model: four boundaries
You can describe most privacy-first health PWAs with four boundaries:
Input boundary (UI). The place where users enter Class A data (pain, symptoms, meds, notes). Design goal: minimize effort and prevent accidental disclosure on-screen.
Validation boundary (schemas). Defensive parsing and normalization (e.g., Zod) so bad/partial input doesn’t corrupt storage. Design goal: accept partial, safe entries; reject unsafe shape changes.
Persistence boundary (local storage). IndexedDB (or similar) with versioned schema and migrations. Design goal: resilient writes, predictable upgrades, and recoverable failure modes.
Export boundary (user-controlled leaving-the-device). PDF/CSV/JSON exports, or clinician-friendly summaries. Design goal: explicit user intent, clear content previews, and minimal surprise.
If you can draw these boundaries, you can reason about nearly every feature request without guessing.
Data classification (why it matters in architecture)
You don’t need a compliance department to benefit from classification.
- Class A: health data (entries, notes, attachments, exports)
- Class B: operational/security events (audit events, error traces, feature flags)
- Class C: preferences (theme, layout, a11y settings)
Architecture implication: treat Class A as “never network by default.” Class B should be structured and non-reconstructive. Class C can be persisted freely but still deserves respect.
A reference data flow (local-first)
Here’s a practical, implementation-agnostic flow that matches PainTracker’s approach:
- User action (log pain episode, update symptoms, add context)
- Validation + normalization (schema-based, tolerant of partial entries)
- State update (predictable store: Zustand/Immer or equivalent)
- Persistence (write to IndexedDB; migrations are explicit)
- Derived views (trends, patterns, summaries computed locally)
- Export (user initiates; app generates clinician/workflow artifacts)
In diagram form:
UI input
-> validate/normalize
-> in-memory state
-> local persistence (IndexedDB)
-> local analytics (derived, non-network)
-> export (user-controlled)
The key property: everything works without the network.
Sync strategy: default “no sync,” optional “explicit sync”
Many apps treat sync as the default because it makes analytics and multi-device access easy. Privacy-first health PWAs treat sync as a privilege that must be earned.
For PainTracker-aligned architecture:
- Default: no cloud sync. Your app is complete without accounts.
- If you add sync later: make it explicit, user-controlled, and auditable.
- Prefer export/import as an intermediate step: users can move data without a background service.
If you can’t describe exactly what leaves the device, when, and why, you’re not ready for sync.
Threat surfaces you inherit (even without a backend)
“No backend” reduces risk, but it does not eliminate risk. You still have:
- Device loss / shared devices: someone else can access the browser profile
- XSS within your origin: any script injection can read on-screen data
- Malicious browser extensions: can scrape DOM and intercept interactions
- Shoulder-surfing: especially in clinics, workplaces, or shared homes
- Accidental oversharing: exports are a common leak vector
Architecture responses tend to fall into two categories:
1) Reduce plaintext exposure (minimize what is displayed and for how long) 2) Strengthen at-rest protection (encryption boundary + lock/unlock patterns)
Important note: be careful with claims. Don’t imply you can protect users from a compromised OS or spyware.
Failure modes (offline-first means you must design for them)
Offline-first is not “works when offline.” It’s “fails safely when everything is weird.”
Plan for:
- IndexedDB quota exhaustion (large notes, attachments, long history)
- Partial writes (crash mid-save, tab killed, mobile OS reclaiming memory)
- Migrations (old schema meets new app version)
- Service worker update mismatch (new UI with old cached assets)
- Clock/timezone drift (timestamp-based trends can be misleading)
- Export generation failures (PDF render fails, file permissions, mobile share sheet quirks)
Each failure mode needs:
- a user-facing message that is non-shaming
- a recovery path (retry, reduce payload, export backup, rollback cache)
- logs/audit events that never contain reconstructive Class A content
A checklist you can implement without guessing
Use this as a quick architecture check for Part 2:
1) Draw the four boundaries (input, validation, persistence, export) 2) List your data classes (A/B/C) and where each is stored 3) Write down your sync stance (none by default; what would trigger change) 4) Enumerate top threat surfaces (XSS, extensions, device loss, exports) 5) Enumerate top failure modes (storage, migration, caching, exports) 6) Decide what you will not claim (no false security guarantees)
Next: Part 3 — Modeling Pain, Not Just Numbers
Next, Part 3 turns architecture into a data model: episodes, context, triggers, work/clinical constraints, and how to avoid the “one score to rule them all” trap.