

Shipping, Observability, and Incident Handling
When something goes wrong in a health tool, the user can lose trust and momentum. Your job is to fix problems without turning the app into surveillance.
Shipping a health-adjacent tool is different from shipping a hobby app.
Reliability is part of care.
And when something breaks, the fix has to respect privacy while still being useful.
But “observability” in a privacy-first app must be handled carefully. The fastest way to betray trust is to quietly collect sensitive information in logs or analytics.
What you can observe without surveillance
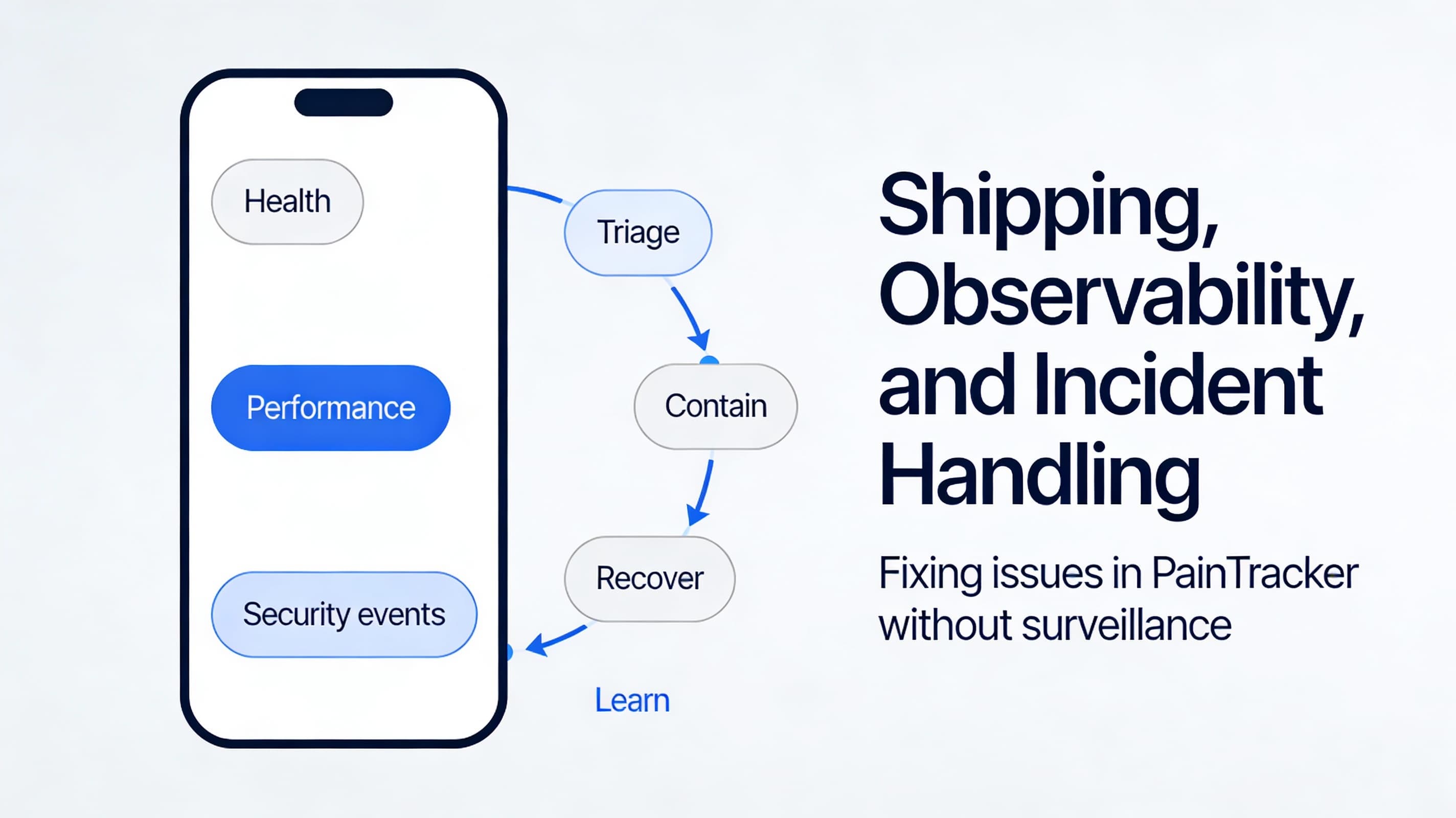
A safe observability posture focuses on:
- app health (crashes, failed writes, migration failures)
- performance (slow screens, long operations)
- security-relevant events (without sensitive payloads)
And avoids:
- capturing raw notes
- capturing export content
- capturing entry payloads
Errors: make them useful, not revealing
Error handling should:
- show non-shaming messages
- preserve user work
- log only what you need to debug (operation name, error type, coarse counts)
If a log line could reconstruct a user’s health entry, it’s too detailed.
Analytics boundaries (if you ever add them)
In a privacy-first health context:
- default is no telemetry
- any analytics must be explicit opt-in
- analytics must be content-free (no Class A)
If you can’t describe the boundary clearly, don’t ship analytics.
Incidents: treat them as learning, not blame
An incident can be:
- data loss risk (migration bug)
- privacy risk (export confusion, unintended disclosure)
- reliability risk (save failures)
Small-team incident loop:
1) Triage: what happened and who is affected? 2) Contain: stop the bleeding (disable feature, add guardrails) 3) Recover: provide user-facing steps 4) Learn: add tests and update the checklist
Shipping quick check
1) Primary flows have explicit error states and recovery paths 2) Logs are redacted and non-reconstructive 3) No default telemetry; any analytics is opt-in and documented 4) A basic incident playbook exists 5) Releases are tested on at least one real device form factor
Next: Part 11 — From PWA to Native: When and How to Branch
Next, Part 11 defines when a PWA is enough and when native becomes worth it, plus how to structure code so you can branch without rewriting your product.



